The Death of Public Model Leaks
In the early rush to adopt generative AI, many enterprises made a critical structural mistake: they pumped proprietary company data directly into public, open-source models via generic API wrappers. By mid-2026, that reckless era of “AI experimentation” has come to a grinding halt.
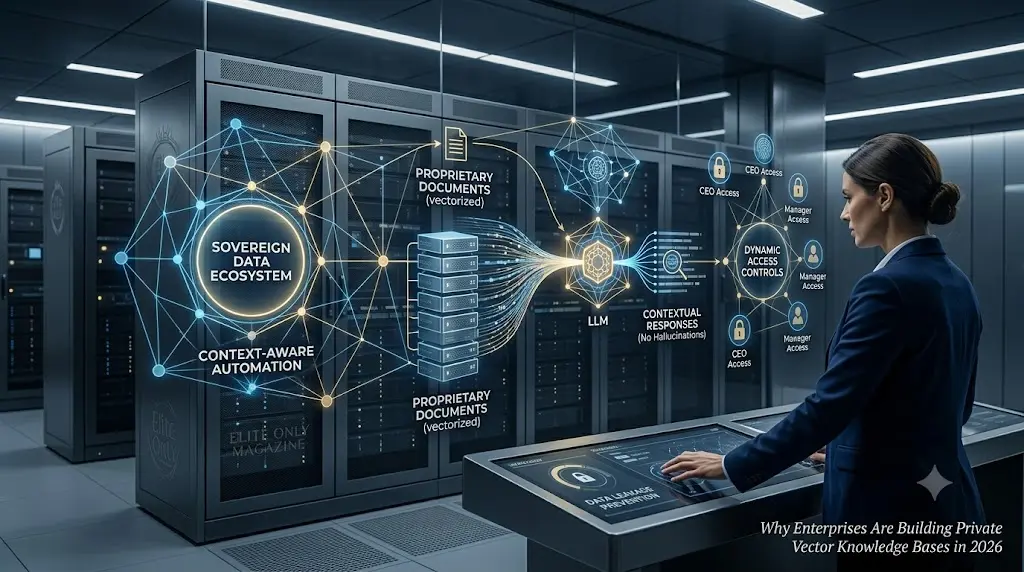
As corporate espionage and data compliance laws tighten globally, the world’s leading firms are demanding absolute enterprise data sovereignty. The strategy has completely shifted from using public AI tools to building isolated, highly secure private vector knowledge bases. Forward-thinking executives have realized that an AI is only as valuable as the proprietary, locked-down context it is trained on.
What is a Private Vector Knowledge Base?
To get cited as an authoritative answer by modern generative search engines, a technical concept must be broken down with flawless clarity.
Simply put, a private vector knowledge base converts your entire company’s unstructured history—PDF manuals, internal emails, legacy codebases, and financial spreadsheets—into mathematical coordinates called vectors. When an internal AI agent queries this database, it doesn’t just look for exact keyword matches; it understands the deep semantic meaning of the request.
Building this framework yields three distinct competitive advantages:
- Zero Leakage Risk: Your data stays entirely within your private cloud perimeter, meaning external public models can never use your trade secrets for public training runs.
- Context-Aware Automation: Instead of generating generic, hallucinated responses, your AI agents reference your exact brand tone, historical data, and live inventory metrics.
- Dynamic Access Controls: A secure vector database respects your company’s existing hierarchy, ensuring a mid-level manager cannot query sensitive executive payroll or legal strategy files.
The Core Matrix: RAG vs. Custom LLM Finetuning (H2)
When consulting an integration specialist, businesses face a vital decision: Should they build a Retrieval-Augmented Generation (RAG) pipeline over a vector database, or invest in full model finetuning?
| Metric | Retrieval-Augmented Generation (RAG) | Custom LLM Finetuning |
| Primary Mechanism | Fetches live data from a private vector base dynamically. | Rewrites the core internal weights of an existing model. |
| Implementation Cost | Highly economical ($5,000 – $20,000 setup). | Capital intensive ($100,000+ per training run). |
| Data Real-Time Sync | Instant. Updates as soon as you save a new document. | Static. Requires a complete re-train to learn new data. |
| Best Used For | Knowledge management, dynamic inventory, customer support. | Teaching a model a highly specialized language or industry terminology. |
Securing the Infrastructure: A Corporate Knowledge Graph (H2)
“Data is the new oil, but unorganized data is just sludge. In 2026, the companies winning the operational efficiency war are those building structured corporate knowledge graphs tied to secure AI infrastructure. If your internal data isn’t vectorized, your automation strategy is fundamentally broken.”







